Image Caption Generation
I developed the Image Captioning model by using the combination of CNN and Transformer. Here, I am using efficientnet from keras application. For the dataset, I have used Flickr8K dataset which comprises of over 8000 images which contains 5 different labels for each image. The architecture of the model can be divided into 3 parts:
1. CNN: It is used to extract image features.
2. Transformer Encoder: The extracted image feature passes through the transformer which creates new representation of the inputs.
3. Transformer Decoder: the encoded input with the text data sequence are passed through the decoder which tries to learn and generate the captions.
However, the model's accuracy can be increased by using alternative datasets such as COCO Caption, Flickr30K, and others, as well as models such as Visual Attention, GAN, and others.

Image Caption Generation

Image Caption Generation

Image Caption Generation
1 of 3
Next Project
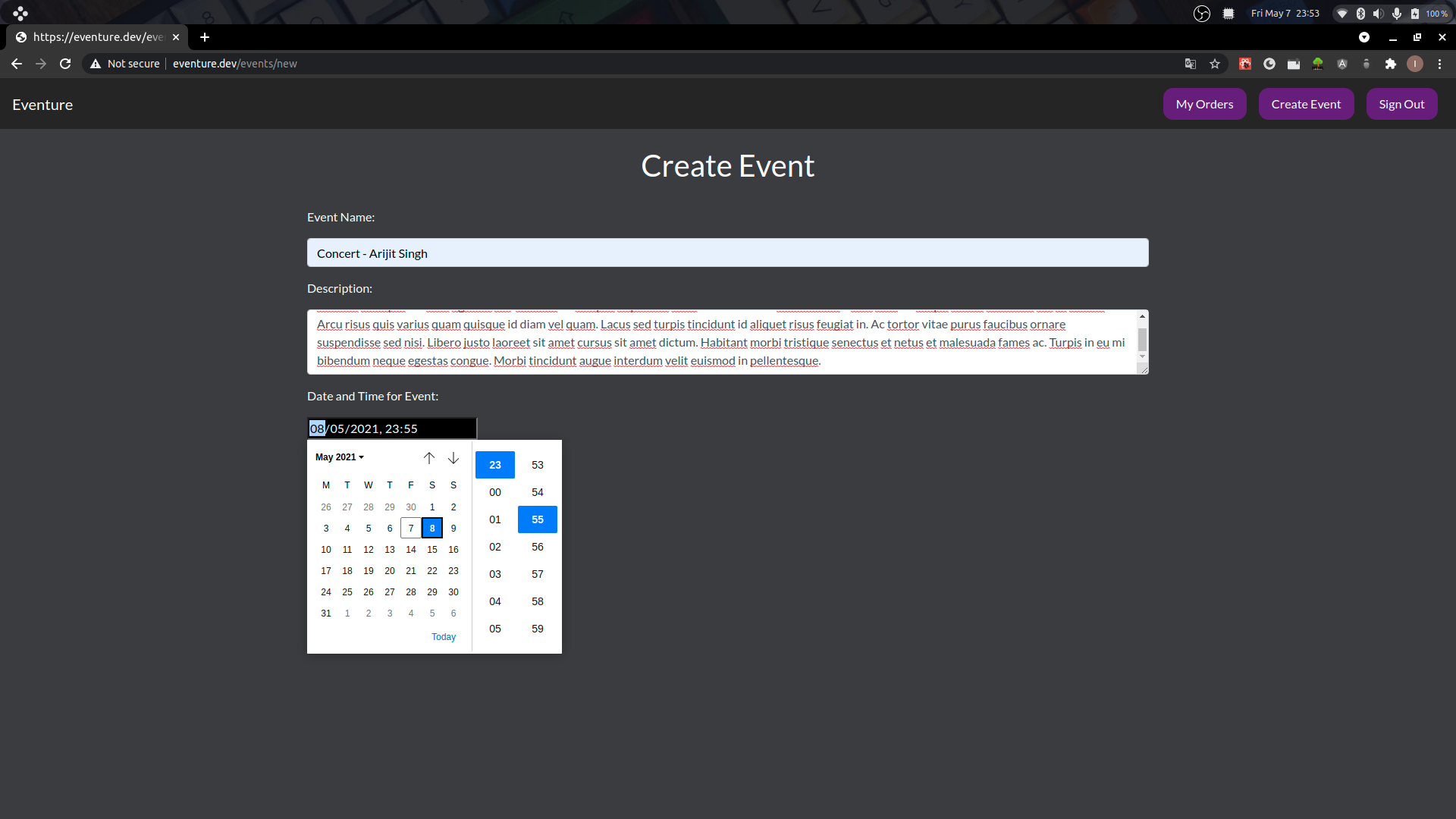
Eventure App